
Python Modules and Command-line Programs
The IPython Notebook and other interactive tools are great for prototyping code and exploring data, but sooner or later one or both of the following things happen:
We develop a useful function that we want to use in other notebooks and we know that there has to be a better way than copying and pasting it around.
We want to use the useful function we've created in a pipeline or run via a shell script to process thousands of data files.
In order to do reach those goals, we need to:
- Store our functions in a Python module
- Put a wrapper around them to make a program that works like other Unix command-line tools
An example of a command-line script that uses our sherlock() function to process groups of files would look like:
$ python sherlock.py inflammation-*or
$ python sherlock.py inflammation-0[6-9].csvTo make this work, we need to know how to handle command-line arguments in a program, and how to get at standard input.
Objectives
- Create a Python module containing functions that can be
import-ed into notebooks and other modules. - Use the values of command-line arguments in a program.
- Read data from standard input in a program so that it can be used in a pipeline.
Python Modules
A Python module is just a text file that contains some Python functions. Once we have our functions in a module we can use the import statement to bring them into any number of iPython Notebooks, or into other Python modules.
So, let's put our sherlock() and plot_clues() functions into a text file called sherlock.py. We could:
- Open an empty file called
sherlock.pyin our favourite text editor and type the functions again - Use copy and paste to scoop the functions from the
04-simple_condnotebook into the file - Use the iPython Notebook
%%writefilecell magic to write the functions out of the notebook into the file
We'll use %%writefile because it's the least work.
%%writefile?
Type: Magic function
String form: <bound method OSMagics.writefile of <IPython.core.magics.osm.OSMagics object at 0x7fa01a2926d0>>
Namespace: IPython internal
File: /home/dlatornell/anaconda3/envs/swc/lib/python2.7/site-packages/IPython/core/magics/osm.py
Definition: %%writefile(self, line, cell)
Docstring:
::
%writefile [-a] filename
Write the contents of the cell to a file.
The file will be overwritten unless the -a (--append) flag is specified.
positional arguments:
filename file to write
optional arguments:
-a, --append Append contents of the cell to an existing file. The file will
be created if it does not exist.To write our sherlock() and plot_clues() functions to a Python module files called sherlock.py put
%%writefile sherlock.pyat the top of the cell containing the functions and execute the cell. The results message will tell us that the contents of the cell have been written to a file instead of having been executed.
Don't forget to delete the %%writefile line from the top of the cell before you save the notebook.
We also need the analyze_stats() function because sherlock() calls that too. Use
%%writefile -a sherlock.pyto append it to our sherlock.py module.
When we're done sherlock.py should contain:
!cat sherlock.py
def sherlock(filenames, datalen=40):
datamax = np.empty((len(filenames), datalen))
for count, f in enumerate(filenames):
datamax[count] = analyze_stats(f)[1]
plot_clues(datamax)
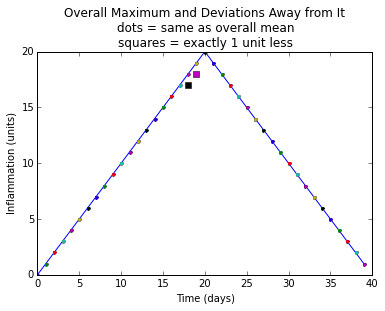
def plot_clues(datamax):
overallmax = datamax.max(0)
plt.plot(overallmax)
size = datamax.shape
for count in range(size[0]):
for time in range(size[1]):
if datamax[count, time] - overallmax[time] == -1:
plt.plot(time, datamax[count, time], 's')
elif datamax[count, time] < overallmax[time]:
plt.plot(time, datamax[count, time], 'x')
else:
plt.plot(time, datamax[count, time], '.')
plt.title(
"Overall Maximum and Deviations Away from It\n"
"dots = same as overall mean\n"
"squares = exactly 1 unit less")
plt.xlabel("Time (days)")
plt.ylabel("Inflammation (units)")
plt.show()def analyze_stats(filename):
data = np.loadtxt(fname=filename, delimiter=',')
return data.mean(0), data.max(0), data.min(0)
Now that we have our code in a text file we'll shift to our favourite text editor to make changes.
The first thing we need to do is import the modules that sherlock() and plot_clues() use.
In your editor, add the following lines to the top of the file, and save it.
import matplotlib.pyplot as plt
import numpy as npBy convention, imports are written in alphabetical order.
We also need to fix how the definition of analyze_stats() was appended to the file by adding a couple of empty lines and making sure that the indentation is correct.
After doing those things sherlock.py should look like:
!cat sherlock.py
import numpy as np
import matplotlib.pyplot as plt
def sherlock(filenames, datalen=40):
datamax = np.empty((len(filenames), datalen))
for count, f in enumerate(filenames):
datamax[count] = analyze_stats(f)[1]
plot_clues(datamax)
def plot_clues(datamax):
overallmax = datamax.max(0)
plt.plot(overallmax)
size = datamax.shape
for count in range(size[0]):
for time in range(size[1]):
if datamax[count, time] - overallmax[time] == -1:
plt.plot(time, datamax[count, time], 's')
elif datamax[count, time] < overallmax[time]:
plt.plot(time, datamax[count, time], 'x')
else:
plt.plot(time, datamax[count, time], '.')
plt.title(
"Overall Maximum and Deviations Away from It\n"
"dots = same as overall mean\n"
"squares = exactly 1 unit less")
plt.xlabel("Time (days)")
plt.ylabel("Inflammation (units)")
plt.show()
def analyze_stats(filename):
data = np.loadtxt(fname=filename, delimiter=',')
return data.mean(0), data.max(0), data.min(0)
Now, we can import our sherlock() function and use it just in this notebook just like we used it in the previous notebook where we developed it:
%matplotlib inline
import glob
import sherlock
sherlock.sherlock(glob.glob('inflammation-*.csv'))
Docstrings
Let's add some docstrings to our module and its functions to tell our future selves and others what the code does. Recall the the convention for docstrings is to enclose them in sets of triple double quotes: """. The module docstring goes at the top of the module (before the imports), and the function docstrings go at the tops of the functions (just after the def statements).
Once we have some docstring in our module we can reload it into the notebook and use the help features to check them out.
reload(sherlock)
<module 'sherlock' from 'sherlock.pyc'>
Reload?
The import statement only works once during a Python session. After that, Python will not reread your code, no matter how many times you import it. This means that if you import your code from a file, then change and save the file, those changes won't be reflected in Python, even if you
importyour module again. To explicitly force Python to reread your module after a change, use thereload()function.
sherlock?
Type: module
String form: <module 'sherlock' from 'sherlock.pyc'>
File: /home/dlatornell/swc/2014-09-25-ubc/novice/python/sherlock.py
Docstring:
Investigate the suspicious similarities in the inflammation data files.
Plot a graph that shows how little the per-dataset maximum inflammation
deviates from the overal maximum value.sherlock.sherlock?
Type: function
String form: <function sherlock at 0x7f303dde68c0>
File: /home/dlatornell/swc/2014-09-25-ubc/novice/python/sherlock.py
Definition: sherlock.sherlock(filenames, datalen=40)
Docstring:
Detect the suspicious lack of differences in the maximum
inflamation values.Command-Line Arguments
Use your editor to create a new file called argv-list.py that contains the lines:
import sys
print 'sys.argv is', sys.argvThat strange name argv stands for "argument values". Whenever Python runs a program, it takes all of the values given on the command line and puts them in the list sys.argv so that the program can determine what they were.
If we use Python to run this program at the command-line:
$ python argv-list.pyThe output should look something like:
sys.argv is ['argv-list.py']and if we run it from a different directory, we get:
$ cd ..
$ python hbridge/argv-list.py
sys.argv is ['hbridge/argv-list.py']The only thing in the list is the path to our script, which is always sys.argv[0]. If we run it with a few arguments, however:
$ python hbridge/argv-list.py one two three
sys.argv is ['hbridge/argv-list.py', 'one', 'two', 'three']then Python adds each of those arguments to the list.
With that knowledge we can add a feature to our sherlock.py module to enable us to run sherlock from the command-line and pass in the list of files that we want it to operate on via shell wildcard characters.
In your text editor, add
import systo the collection of import statements at the top of the sherlock.py file, and add a new function definition:
def main():
"""Command-line interface.
"""
script = sys.argv[0]
files = sys.argv[1:]
for fn in files:
print fnThe main() function is the function that we're going to call when the module is executed by Python from the command-line. It's a Python convention to call it main(), but you could call it anything else if you wanted to. At this point main() is just a "stub" for testing - it doesn't call sherlock() yet, but we'll get there...
We need to call the main() when we do:
$ python sherlock.pybut we also want to still be able to use:
import sherlockin our code as we did a few minutes ago. There is a detail that we need to take care of for things to work both ways.
When Python imports a module it executes the code in the module. If we just put a call to main() in sherlock.py it will be executed whenever we do import sherlock, perhaps with unpleasant (or unexpected) results. That's what's known as an "import side-effect" and it's bad form in Python programming. Fortunately, Python provides a way to solve this problem. There is a special variable, __name__, which is set when Python reads a module. If Python is reading the module because it has been run from the command-line, __name__ is set to "__main__", but if the module is being read because it is being imported, __name__ is set to the name of the module.
We can use that to ensure that our main() function is only executed when the module is run at the command-line by adding these 2 lines of code to the end of sherlock.py:
if __name__ == '__main__':
main()With those changes in place, here's what sherlock.py looks like now:
!cat sherlock.py
"""Investigate the suspicious similarities in the inflammation data files.
Plot a graph that shows how little the per-dataset maximum inflammation
deviates from the overal maximum value.
"""
import sys
import numpy as np
import matplotlib.pyplot as plt
def main():
"""Command-line interface.
"""
script = sys.argv[0]
files = sys.argv[1:]
sherlock(files)
def sherlock(filenames, datalen=40):
"""Detect the suspicious lack of differences in the maximum
inflamation values.
"""
datamax = np.empty((len(filenames), datalen))
for count, f in enumerate(filenames):
datamax[count] = analyze_stats(f)[1]
count += 1
plot_clues(datamax)
def plot_clues(datamax):
overallmax = datamax.max(0)
plt.plot(overallmax)
size = datamax.shape
for count in range(size[0]):
for time in range(size[1]):
if datamax[count, time] - overallmax[time] == -1:
plt.plot(time, datamax[count, time], 's')
elif datamax[count, time] < overallmax[time]:
plt.plot(time, datamax[count, time], 'x')
else:
plt.plot(time, datamax[count, time], '.')
plt.title(
"Overall Maximum and Deviations Away from It\n"
"dots = same as overall mean\n"
"squares = exactly 1 unit less")
plt.xlabel("Time (days)")
plt.ylabel("Inflammation (units)")
plt.show()
def analyze_stats(filename):
data = np.loadtxt(fname=filename, delimiter=',')
return data.mean(0), data.max(0), data.min(0)
if __name__ == '__main__':
main()
Let's test it!
$ python sherlock.py inflammation-01.csv
inflammation-01.csv$ python sherlock.py inflammation-*.csv
inflammation-01.csv
inflammation-02.csv
inflammation-03.csv
inflammation-04.csv
inflammation-05.csv
inflammation-06.csv
inflammation-07.csv
inflammation-08.csv
inflammation-09.csv
inflammation-10.csv
inflammation-11.csv
inflammation-12.csv$ python sherlock.py inflammation-0[6-9].csv
inflammation-06.csv
inflammation-07.csv
inflammation-08.csv
inflammation-09.csvAs expected, sherlock.py is printing out the list of files that we are asking for with the shell wildcard characters. So, it's just a small change now to call the sherlock() function on that list:
def main():
"""Command-line interface.
"""
script = sys.argv[0]
files = sys.argv[1:]
sherlock(files)Now, when we run
$ python sherlock.py inflammation-*.csva Matplotlib graph window pops open:
matplotlib graph window
It has tool buttons to let you pan and zoom in the image, and also to save the image to a file.
In summary:
- We started with some functions that we developed in a
notebookbut that we decided we wanted to use elsewhere. - We captured those functions in a Python module (
sherlock.py) with the help of the IPython Notebook%%writefilecell magic. - We modified the module in a text editor to add imports and docstrings.
- We demonstrated that we could import from our
sherlock.pymodule, and use the help features of IPython to read our docstrings. - We modified
sherlock.pyso that it could be used as a command-line script as well as an import. - We used the
sherlock()function to produce graphs both in-line in an IPython Notebook, and in a separate graph window.
This is an example of code re-use and the DRY (Don't Repeat Yourself) principle. We developed sherlock() and its associated functions in one context and made them useful in other ways without having to copy/paste them and maintain multiple versions.
Connecting to the Pipeline
Although it doesn't make much sense in the context of sherlock, you can probably imagine wanting to write a Python script that you could use as part of a shell pipeline:
$ python myscript.py < inflammation-*.csv | head -20Python provides a special "file" called sys.stdin, which is automatically connected to the program's standard input. We don't have to open it — Python and the operating system take care of that when the program starts up — but we can do almost anything with it that we could do to a regular file.
We can use that in a main() function like this:
def main():
script = sys.argv[0]
filenames = sys.argv[1:]
if not filenames:
process(sys.stdin)
else:
process(filenames)Argparse
Creating command-line scripts with multiple arguments, option flags, built-in help, etc. is a common enough task that people have written Python libraries to take care of most of the tedious details. The Python standard library has a module named argparse that does that. When you want to get serious about creating Python command-line scripts you should go to Tshepang Lekhonkhobe's Argparse tutorial that is part of Python's Official Documentation.
Key Points
- A Python module is a text file containing Python code.
%%writefilelets you output code developed in a Notebook to a Python module.- The
syslibrary connects a Python program to the system it is running on. - The list
sys.argvcontains the command-line arguments that a program was run with. if __name__ == "__main__":provides a shield that prevents code in a module from being executed when the module is imported, but allows it to be run from the command-line.- The "file"
sys.stdinconnects to a program's standard input.